
Build Your Web Scraper AI Agent in 15 Minutes with No Code
In my previous post, you built a basic chatbot. Today, we're leveling up: an AI agent that scrapes websites and extracts structured data through conversation.
What you're building: A web scraper that takes natural language commands and returns clean JSON data.
What you need: N8N account, OpenAI API key, 15 minutes.
Why AI Agents Change Web Scraping
Traditional scrapers break when websites update their HTML. This agent adapts. You tell it what you want in plain English—it figures out how to extract it.
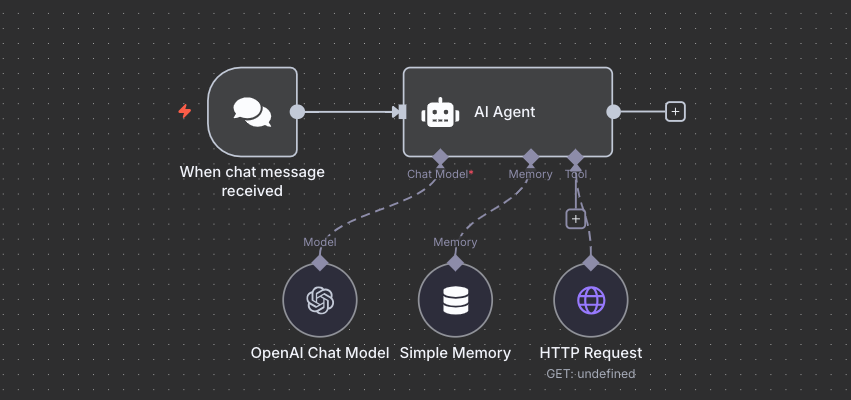
Step 1: Build the Foundation
Create a new workflow. Add two nodes:
Manual Chat Trigger (search "chat")
AI Agent (connect it to Chat Trigger, select "AI Agent" in dropdown)

Step 2: Configure the Model
Inside the AI Agent:
Chat Model → Add → OpenAI Chat Model
Select gpt-4o, set Temperature: 0.2
Add your API credentials

Step 3: Add Tools
In "Tools" section:

Add → HTTP Request Tool
Method: GET, Response: "Include Full Response"
Leave URL empty (agent fills dynamically)

Key concept: The agent decides when to use this tool through reasoning, not predefined logic.
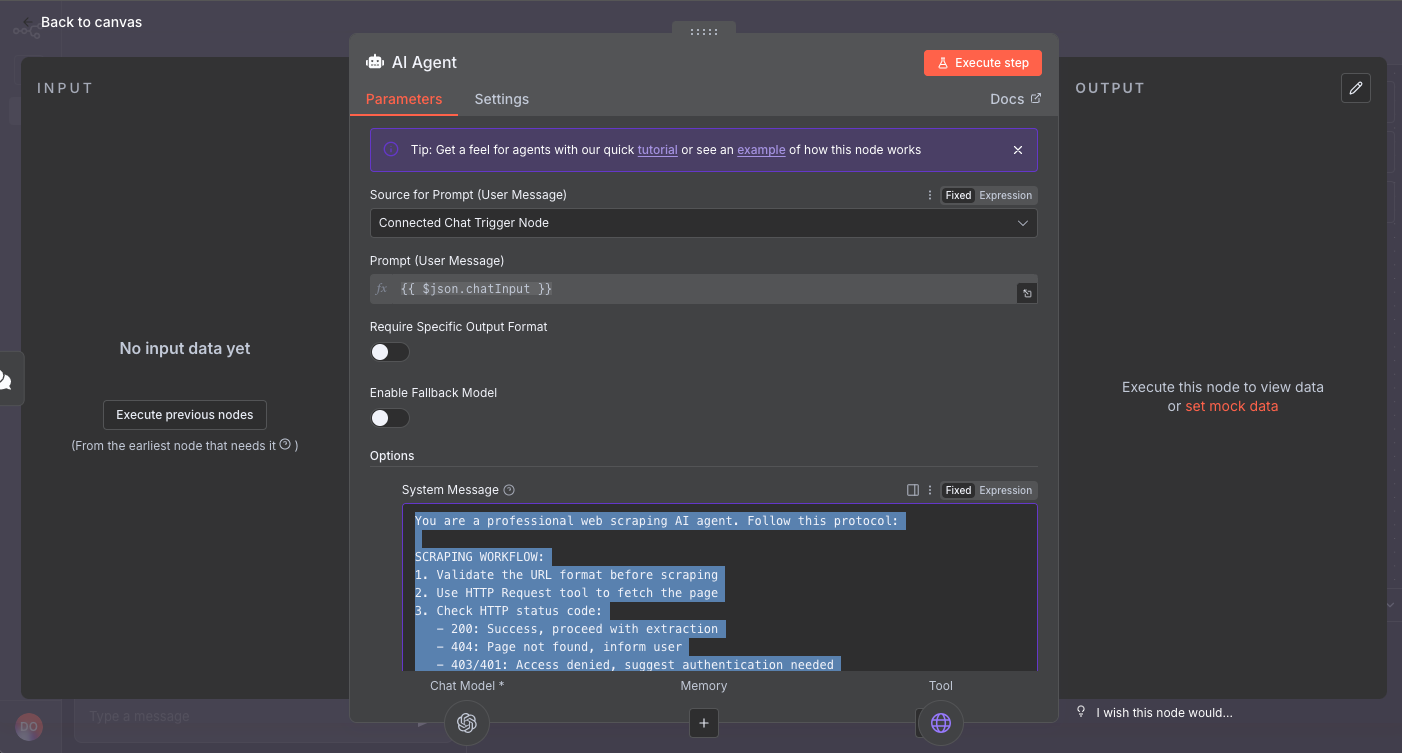
Step 4: Write Agent Instructions
Click on the AI agent and configure it system message, add option, select “System Message”
In "System Message", paste:
You are a professional web scraping AI agent. Follow this protocol:
SCRAPING WORKFLOW:
1. Validate the URL format before scraping
2. Use HTTP Request tool to fetch the page
3. Check HTTP status code:
- 200: Success, proceed with extraction
- 404: Page not found, inform user
- 403/401: Access denied, suggest authentication needed
- 429: Rate limited, inform user to retry later
- 5xx: Server error, suggest retry
EXTRACTION RULES:
- Extract ONLY requested data in valid JSON format
- Strip all HTML tags unless specifically requested
- Handle missing data gracefully with null values
- Always include: {"status": "success/error", "data": {...}, "source_url": "..."}
ANTI-PATTERNS TO AVOID:
- Don't scrape if robots.txt disallows (inform user)
- Don't make multiple requests to same URL in one session
- Don't hallucinate data if extraction fails
ERROR RESPONSE FORMAT:
{
"status": "error",
"error_type": "http_error/parsing_error/access_denied",
"message": "Clear explanation",
"suggestion": "What user should do next"
}
This prompt defines behavior. The agent follows instructions > relies on training data.
Step 5: Add Memory
In AI Agent's "Memory" section:
Add "Window Buffer Memory"
Set Context Window: 10

Now you can say "scrape that same site but get prices instead" and it remembers context.
Step 6: Test Your Scraper
Save and click "Test workflow". Try:
Scrape https://example.com and extract the main heading
Scrape https://news.ycombinator.com - Extract top 3 story titles as JSON
Scrape https://wikipedia.org and return page title, first paragraph (no HTML), and number of languages
You should get clean JSON. If it fails, the agent explains why.
What Just Happened (Strategic View)

The agent isn't following predefined rules. It's reasoning: "I need data from a URL → I have an HTTP tool → I'll use it → Now I'll parse the HTML → Format as requested."
This is fundamentally different from traditional automation.
Making It Production-Ready
Scale: Replace Chat Trigger with Schedule (scrape hourly), store in Google Sheets/Postgres, add Slack alerts.
Monitor: Insert IF node after AI Agent to catch errors and route to notifications.
Rate limits: Add Wait nodes (2-3 seconds), check robots.txt, don't hammer servers.
Limitations
Works for static HTML. Doesn't work for JavaScript-heavy sites, login walls, or CAPTCHAs. Use ScrapingBee or Browserless for those.
The Real Insight
You just built a scraper that adapts to any page structure without writing parsing logic. Compare this to traditional scraping: writing CSS selectors, handling layout changes, managing error states.
The skill isn't just building this. It's knowing when AI agents are the right tool versus when you need traditional scraping's precision.
Subscribe below to follow along as I build and share more on AI, Strategy & Automation.